
Subtitle: The hardware operator’s guide to Over-the-Air (OTA) updates, Digital Twins, and remote debugging in the 2026 stack.
1. The Nightmare of Scale
Building a prototype is a joy. You have one ESP32 on your desk, a USB cable, and a Serial Monitor. But the moment you move from 1 device to 1,000 devices deployed globally, the joy turns into a logistical nightmare.
What happens when a firmware bug surfaces at 3:00 AM? You can't ask 1,000 customers to "plug in a USB cable and flash this .bin file."
In 2026, the success of a Physical SaaS isn't measured by how cool the hardware is—it’s measured by how much control you have over that hardware when it’s 5,000 miles away. As soon as you become a fleet operator, your real job title quietly shifts from “engineer” to “orchestrator”.This post covers the three pillars of fleet management: Atomic Updates, Device Shadows, and Remote Observability.
Takeaway: If you can’t change or inspect a device without touching it, you don’t have a fleet—you have a collection of liabilities.
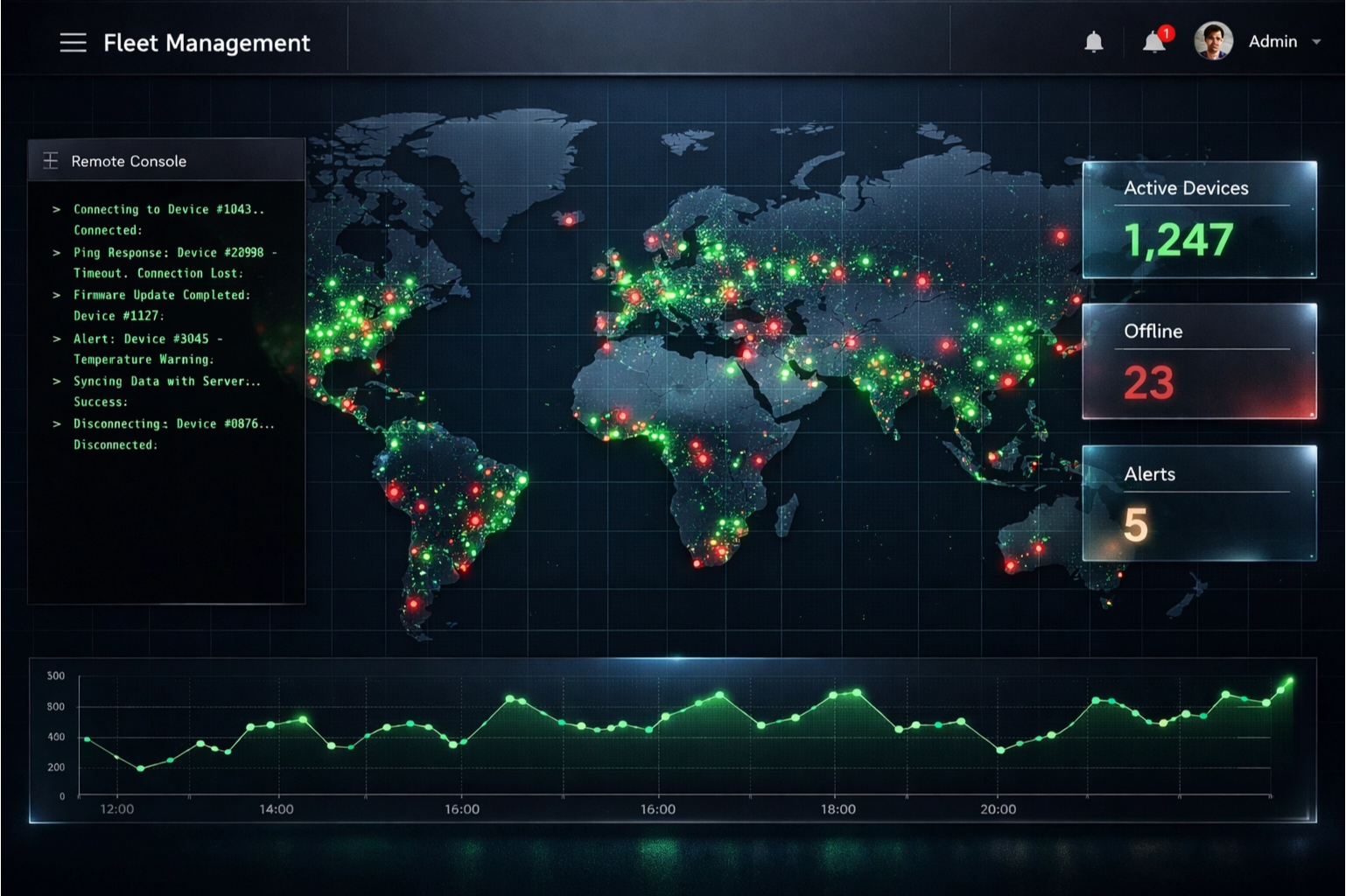
2. Pillar 1: Atomic OTA (Over-the-Air) Updates
The biggest risk in hardware is a "Bricked Device"—a machine that fails during an update and can no longer boot.
The 2026 Standard: Dual-Slot A/B Updates
Professional fleets do not overwrite their running code. They use Dual-Slot Banking:
- Slot A is currently running the production code.
- The new firmware is downloaded into Slot B in the background.
- The device performs a checksum verification (using the HMAC keys we discussed in Part 5).
- If the signature is valid, the bootloader switches to Slot B and reboots.
- The Safety Net: If Slot B fails to "heartbeat" within 60 seconds of booting, the hardware automatically rolls back to Slot A.
For extra safety, you rarely roll out to 100% of the fleet at once. A canary strategy—e.g., first 1–5% of devices, then 20%, then the full fleet—lets you catch bad firmware before it bricks thousands of units.
Infrastructure Tip: Use Cloudflare R2 (from Part 6) to host your firmware binaries. It’s globally distributed and has zero egress fees, making it the perfect "Firmware CDN."
Takeaway: Every device should be able to update and unbrick itself, without you or your customer ever touching a USB cable.
3. Pillar 2: The Digital Twin (Shadow Sync) Pattern
Physical devices are not always online. A user might change a setting on your Next.js dashboard while the device is in a tunnel or powered off.
The Shadow Architecture
In 2026, we don't send commands directly to devices. We use a Desired vs. Reported state pattern in the database:
- Desired State: What the user wants (e.g., "Set fan speed to 80%").
- Reported State: What the hardware last confirmed (e.g., "Fan speed is 20%").
One simple schema could be a device_state record with fields like desired_state (JSON) and reported_state (JSON), plus a last_seen_at timestamp. Your dashboard writes to desired_state; devices periodically read from it, apply changes, and then overwrite reported_state.
When the device reconnects, it checks the "Desired" table, applies the changes, and updates the "Reported" state. This ensures a seamless UX where the dashboard always feels responsive, even if the atoms haven't caught up with the bits yet.
Takeaway: Users talk to the shadow; devices just catch up when they can.
4. Pillar 3: Remote Debugging & Heartbeat Analytics
When a device fails in the field, you need logs. But you can't stream logs from 1,000 devices simultaneously—it would kill your "Low-Burn" budget.
WebSocket Tunneling & "Health Scores"
- Passive Monitoring: Every 60 seconds, devices send a "Heartbeat" (vitals like battery, RSSI, and CPU temp).
- AI-Driven Anomalies: Use a lightweight Agent to monitor these heartbeats. If one device’s temperature starts drifting away from the fleet average, the Agent flags it for inspection before it fails.
- Active Debugging: Implement a "Debug Mode" in your dashboard. When toggled, it opens a secure WebSocket tunnel to that specific device, streaming real-time Serial logs to your browser. It’s like being there with a USB cable, without the flight.
Access to Debug Mode should be locked behind short-lived, signed links or admin-only permissions, so your “remote USB cable” doesn’t turn into a security backdoor.
Takeaway: You don’t stream everything—you stream the right thing, from the right device, at the moment it matters.
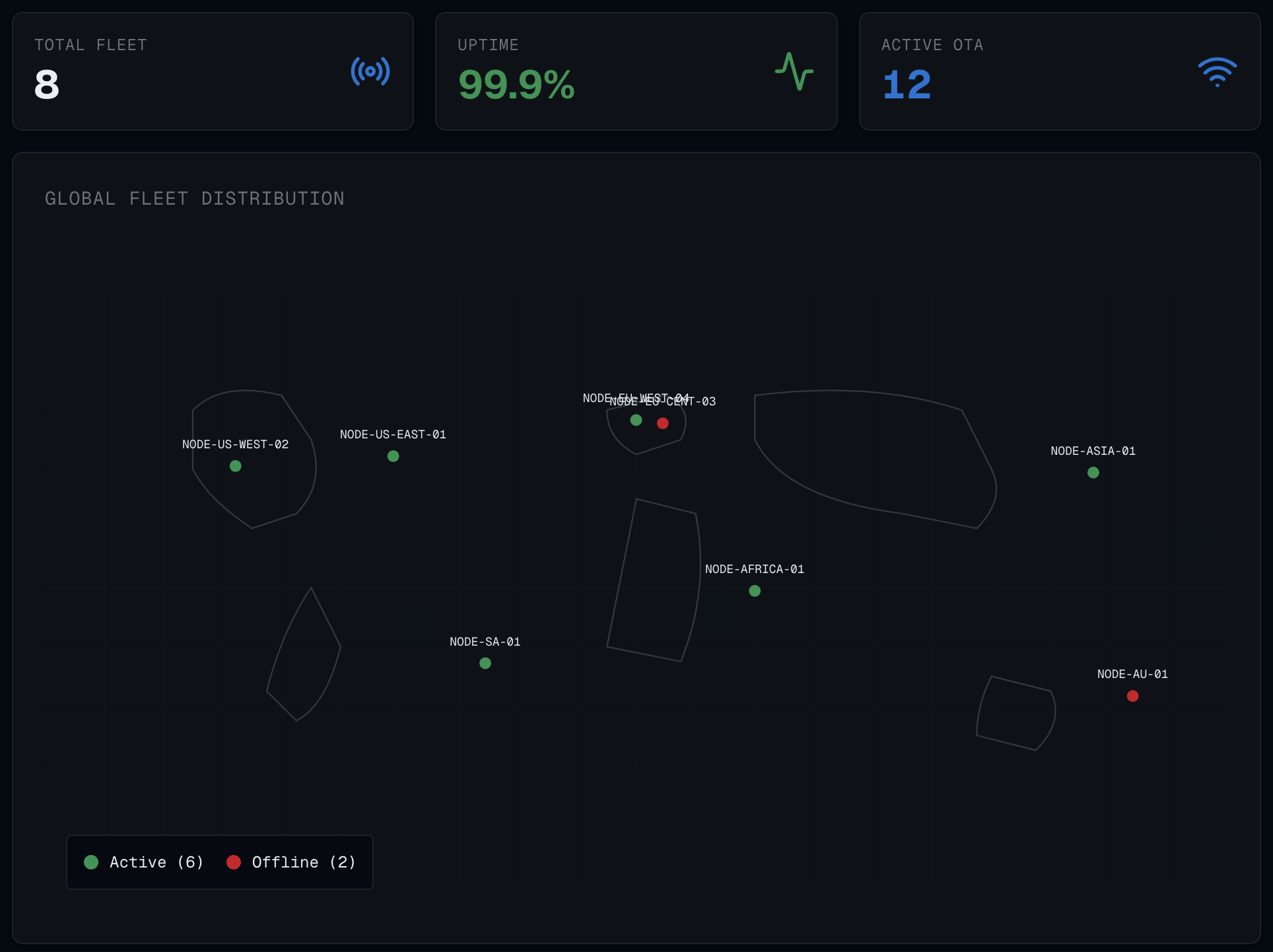
5. Visualizing the Fleet Pipeline
To maintain this, your CI/CD pipeline must be fully automated.

Takeaway: Treat your devices like any other deploy target—versioned, signed, canaried, and observable end to end.
6. Summary: Control is the Moat
In 2026, the hardware is just the "interface." Your real value as a SaaS founder is the orchestration layer. A fleet that can self-heal, update securely, and report health in real-time is a fleet that can scale to 100,000 units.
Your Fleet Checklist:
- Does my bootloader support A/B slot rollback?
- Is my firmware binary signed and hosted on a zero-egress CDN?
- Do I have a "Desired vs. Reported" state sync in my DB?
- Can I trigger a remote log stream for a single device?
Next Step: We’ve built it, secured it, optimized the cost, and scaled the fleet. But how do we stay productive while managing all this? In Part 8, we’ll talk about Hiring Your First AI Employee—automating growth, support, and SEO using a Multi-Agent orchestration that ties back to the Agentic Stack from Part 1 and closes the loop between code, hardware, and autonomous operations.